- 关于我们
- 新闻资讯
从超节点看未来算力中心发展趋势
发布时间:2025-08-29【导言】
黄教主明确指出,英伟达提供的不仅仅是芯片,而是解决方案。在这个Generative AI向Agentic AI演化的大时代,算力的需求才刚刚开启通往星辰大海的闸门。高密度的算力基础设施,对于供电、冷却、大规模并行计算、可扩展性等方方面面带来持续的挑战。超节点作为高度集成的完整算力交付单元,将成为新一代算力中心快速建设和高质量运营的关键抓手设备,也是从系统视角去研究算力基础设施的最佳载体。
一、引言
数字经济时代,算力如同 “新引擎” 对各行业的关键驱动作用,从互联网到制造业,从医疗到科研等领域,算力需求的增长推动了技术的革新与产业的升级。作为算力时代的核心资产,算力中心的发展也日新月异,近期WAIC上多家国产GPU厂商发布了他们的超节点产品,掀起了有关超节点这一技术的讨论热潮。 超节点(SuperPod)并非传统意义上的单一硬件设备,而是指具备集中化管理、大规模资源整合、高性能调度能力的“逻辑节点”或“物理节点集群”。它是数据中心为应对海量数据处理、高并发业务、复杂集群管理需求而演化出的核心组件,本质是通过“资源聚合”和“功能升级”,解决普通节点(如单一服务器)在规模、效率、可靠性上的瓶颈。 本文尝试从超节点的视角探讨未来算力中心发展趋势,借助分析这一行业走向来看未来算力中心的建设可能会出现哪些方面的技术创新。 二、超节点技术剖析
训练侧,大模型在Scaling Law的飞轮下,参数量已经突破万亿级别,海量参数的训练过程中对于显存的容量和带宽都提出了更高的要求。此外,TP、EP等多种并行计算方式的引入带来了大量All-to-All 通信,训练所需的大集群面临如何动态地将模型工作中的负载分配给整个GPU系统,实现更高的GPU利用率的考验。 而推理侧,随着我们从生成式AI(Generative AI)向代理AI(Agentic AI)时代演进,推理产生的token量正以更陡峭的斜率在成倍增加。为了使数据中心这个AI工厂在更大的吞吐量下有更低的时延,需要从计算、通信、软件架构等多个层面共同进行优化,以追求极致的经济效益。 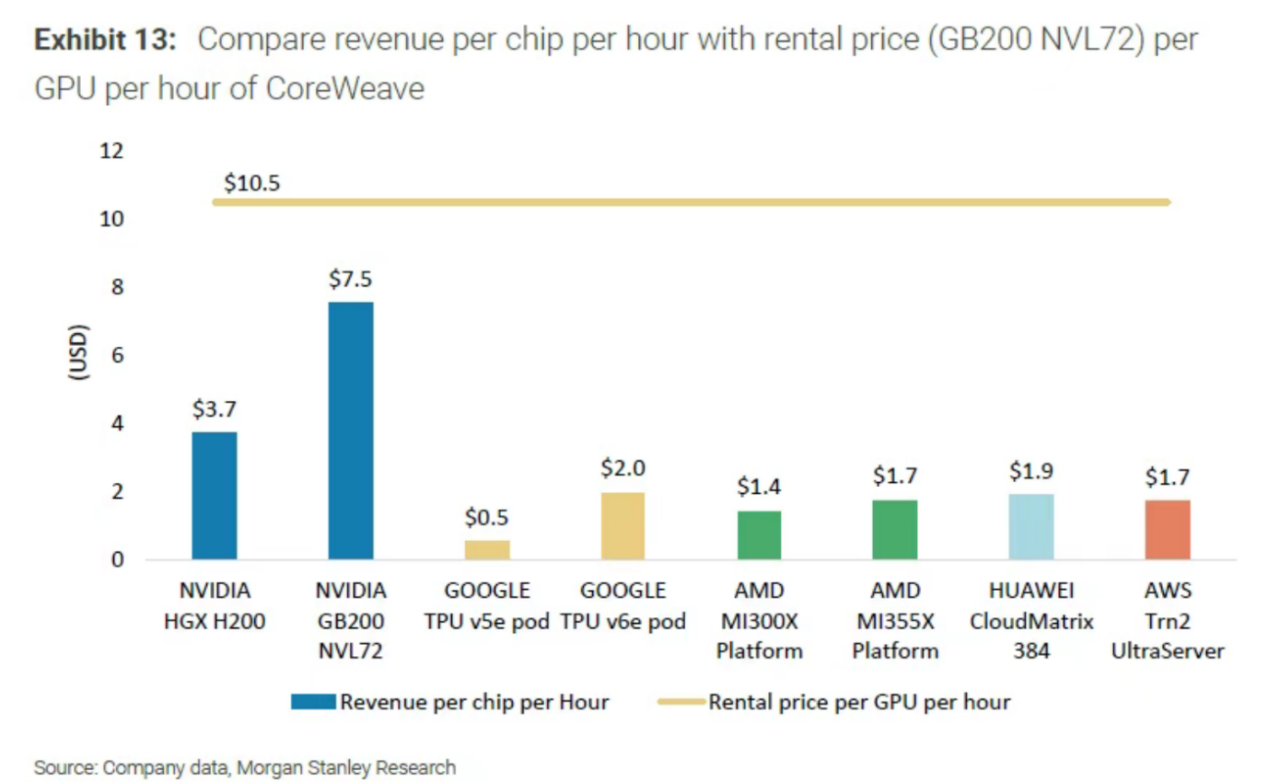
传统数据中心以服务器为基本单元,通过算力设备的增加来实现算力的增长,其通信带宽及计算资源协同发展面临瓶颈,已经无法满足这种大规模、高并发算力需求,算力的有效利用率较低。为了在有限的资源下实现更高效的计算,超节点应运而生,通过对计算、存储、通信等要素进行系统性的重构,使得单节点内的算力密度出现成倍的提升,打造出机架级的超级计算单元,整个系统的能耗比得到显著优化。 三、典型的超节点及其构成 1、英伟达NVL72:高密度柜集大成者 NVL72 在单个机柜内通过 NVLink 技术将36个Grace CPU和72个 Blackwell GPU整合在一起,形成一个高带宽、低延迟的统一计算单元。每颗 B200 GPU支持18条NVLink 5链路,每条链路双向带宽100 GB/s,72颗这样的GPU通过9个NVLink Switch Tray形成总带宽为130TB/s的全mesh网络,在这个网络里,所有GPU之间实现了点对点的全互联,可以任意访问其他GPU的内存空间。 NVLink解决了传统分布式训练中计算与通信失衡的根本矛盾,这种全互联无阻塞架构,极大减少大模型训练中的通信瓶颈,消除因通信延迟导致的计算单元空转,使得单机柜的算力密度极大提升。NVL72是一次AI算力范式的革新,一个机柜相当于一个浓缩的传统集群,将大模型训练从分布式协作升级为超级单体计算。 
2、华为CM384:系统级的重构 CloudMatrix 384由384颗昇腾910C芯片通过全连接拓扑结构互联而成。CloudMatrix 384超级节点横跨16个机架,其中12个计算柜共承载48个昇腾910C服务器节点(总计384个NPU),以及4个通信设备柜(灵衢总线设备柜);每个计算柜包含4个Atlas 900 A3 SuperPoD计算节点,每个节点包括8个昇腾910C神经网络处理单元和4个鲲鹏中央处理器。 这种设计通过规模效应实现性能跃升,尽管单颗昇腾芯片的性能仅为英伟达Blackwell GPU的三分之一,但五倍于后者芯片的数量足以弥补这一差距。完整的CloudMatrix系统现在可以提供300PFLOPs的密集型BF16计算能力,几乎是GB200 NVL72的两倍。其总内存容量超过后者的3.6倍,内存带宽提升2.1倍,标志着华为及中国AI系统能力已全面跻身国际领先行列。昇腾384采用对等计算架构,打破传统以CPU为中心的层级架构。CPU和NPU在逻辑上地位平等,均可直接通信,无需通过CPU中转。这种设计降低了通信延迟,提供了系统整体性能,尤其适用于大规模分布式计算场景。 
四、发展超节点面临的挑战与机会
超节点作为系统级的重构,涉及到诸多硬件层面的挑战,在算力密度指数级增加的情况下,电力供应及散热等配套硬件均面临极限挑战,未来如何在规模化的部署中去平衡性能与成本并实现稳定的运行,将成为下一步行业实践中的主要优化方向。 1、芯片集成密度带来散热挑战 算力芯片的性能提升带来的功耗增长明显,以英伟达为例,H100单芯片功耗约为700W,而至B200时期单芯片的功耗增长至1200W,机架内的高功率密度使得风冷几乎失效,未来服务器内液冷成为标配,目前各家厂商发布的超节点产品均搭配液冷作为冷却方案。 液冷作为一种新兴的冷却技术,通过液态冷却工质流动方式替代风冷的空气换热模式,可以更好地降低芯片核心温度,延长芯片的使用寿命。目前主流的液冷方式包括冷板式和浸没式,冷板式液冷通过金属冷板内部冷却工质的流动对接触面进行冷却,浸没式液冷通过将电子元器件直接浸入冷却工质中进行接触式的散热。 但是如今液冷在实际使用中仍面临诸多工程上的问题,以浸没式为例,因为冷却工质直接接触芯片和服务器内其他部件,容易对于高速信号的完整性造成影响,对于材料兼容性也提出较大要求;此外,机架使用过程中产生的热点分布较为不均,主要集中在GPU、交换机芯片等地方,浸没式液冷在使用中容易因为热点表面的气泡而导致冷却效果受到影响,严重的情况下甚至导致芯片失效。 冷板式液冷凭借其相对低的改造成本以及较为完善的生态率先在多个行业有了典型部署,相比于浸没式,冷板式在应用上更为简单,用户的使用习惯及运维模式与风冷也基本相同。但是尽管冷板式技术已取得显著进展,未来其在超节点中的工程落地仍有较多亟待改进的空间,首先,因为冷板式的冷却的效率主要取决于冷却工质的温度及流速,冷却工质如果降到较低温度,容易在实际使用的过程中在冷板表面形成结露的现象,未来仍需要探索不同方式对这一现象进行改善;其次,液冷设备的可靠性要求极高,需支持上千次插拔零泄漏,一旦冷却工质泄漏可能会导致设备短路烧毁,为了追求更高的可靠性,未来在材料科学(冷却液等)和精密制造(冷板结构、机架结构)等方面都有可能持续的进行技术演进。 2、更高功率带来电能储备挑战 超节点单机柜功耗普遍突破 100kW(如华为 CM384 达 172.8kW,英伟达 GB200 NVL72 约 120-140kW),而且计算密集型任务的脉冲式负载可能导致峰值功耗飙升,如何在电力方案上设置一定冗余以保障机架内硬件的安全成了超节点发展必须面临的挑战。 机器学习的训练任务具有强同步性的特点,在执行矩阵运算等计算密集型任务时,功率需求瞬间攀升到峰值,而在同步通信或数据加载阶段,功率则会骤降,这种瞬时功率的波动幅度极大且频率高,对于供电网络可能会造成损害,目前为了解决这类的电压瞬变的问题,各家厂商主要从软件和硬件层面进行优化。 硬件层面,传统 UPS 无法快速响应,需集成超级电容模组(如 Meta 的 Power Capacitance Shelf)平抑波动。超级电容凭借微秒级响应速度和10 万次以上循环寿命,可吸收 Iteration 切换时的瞬时功率尖峰。同时,机柜级电池备份单元(BBU)也采用锂电池替代铅酸电池,能量密度提升 3 倍,响应时间缩短至微秒级,形成超级电毫秒级瞬态加锂电池秒级稳态的双时间尺度补偿机制。 软件层面,数据中心的供电需要针对性地进行优化,主要是基于历史训练时产生的数据去预测未来的功率曲线,灵活对系统进行预调度。优化后既可以提升能效比,在同样的能耗下提升系统吞吐量,也能够提升系统稳定性,通过软硬件协同的机制平滑抖动。 五、结语 超节点技术推动算力中心架构从分散走向集成,以高密度设计革新布局,未来在超节点的工程实现上仍有众多环节的技术演进存在多种可能,如何能够通过液冷、供电系统等方面的优化去提升系统稳定性成了推动下一代算力中心的核心引擎。 - 新闻资讯